Atlas probes not reporting NTP results on ntp0.testdns.nl ?

Dear list, If anyone knows, or is able to figure out, why most (but not all) Atlas probes don’t report results for NTP measurements to ntp0.testdns.nl, I’d appreciate your insights. Examples: https://atlas.ripe.net/measurements/116922622/ https://atlas.ripe.net/measurements/116946257/ https://atlas.ripe.net/measurements/116830921/ Ping works: https://atlas.ripe.net/measurements/116921717/ Thanks in advance. -- Marco

So Marco ran a measurement and collected pcap files on his ntp server side I then compared what atlas provided for the given measurement, and what Marco ntp server's have seen In short: 44 atlas probes sent and receive NTP responses from Marco's server, but they don't show up in the Atlas results api. See analysis on : https://github.com/gmmoura/ntp-atlas-pcap/blob/main/debug.ipynb /giovane On 10-07-2025 18:01, Marco Davids (SIDN) via ripe-atlas wrote:
Dear list,
If anyone knows, or is able to figure out, why most (but not all) Atlas probes don’t report results for NTP measurements to ntp0.testdns.nl, I’d appreciate your insights.
Examples:
https://atlas.ripe.net/measurements/116922622/
https://atlas.ripe.net/measurements/116946257/
https://atlas.ripe.net/measurements/116830921/
Ping works:
https://atlas.ripe.net/measurements/116921717/
Thanks in advance.
----- To unsubscribe from this mailing list or change your subscription options, please visit: https://mailman.ripe.net/mailman3/lists/ripe-atlas.ripe.net/ As we have migrated to Mailman 3, you will need to create an account with the email matching your subscription before you can change your settings. More details at: https://www.ripe.net/membership/mail/mailman-3-migration/

Hi Marco, Hi Giovane, do you know if this only affects ntp0.testdns.nl or could it be a problem with NTP packets in general? Also, did you do traceroutes/MTRs to the affected probes to see, if there are similarities in routing – like the same transit carrier? In the past, some carriers (CenturyLink, as an example) had traffic filter rules in place on their edges to prevent NTP reflection or amplification attacks, that killed regular NTP traffic as well, so I assume this could be the case here, too, not necessarily with CenturyLink/Colt as the transit. You could try doing a traceroute with port 123/UDP as the source towards these probes to see, if the packets get eaten on some network demarcation: traceroute -U --sport 123 <ip-of-the-probe> You will likely not get an answer on the last 1-2 hops (because NAT and stateful firewalls), but if there's a carrier in between that discards traffic, the traceroute is noticeable shorter. If it helps, you can try with my server ntp2.301-moved.de as well – I have access to sflow data from that host, so I can precisely tell if there have been answer packets coming from that system. Greetings, Max

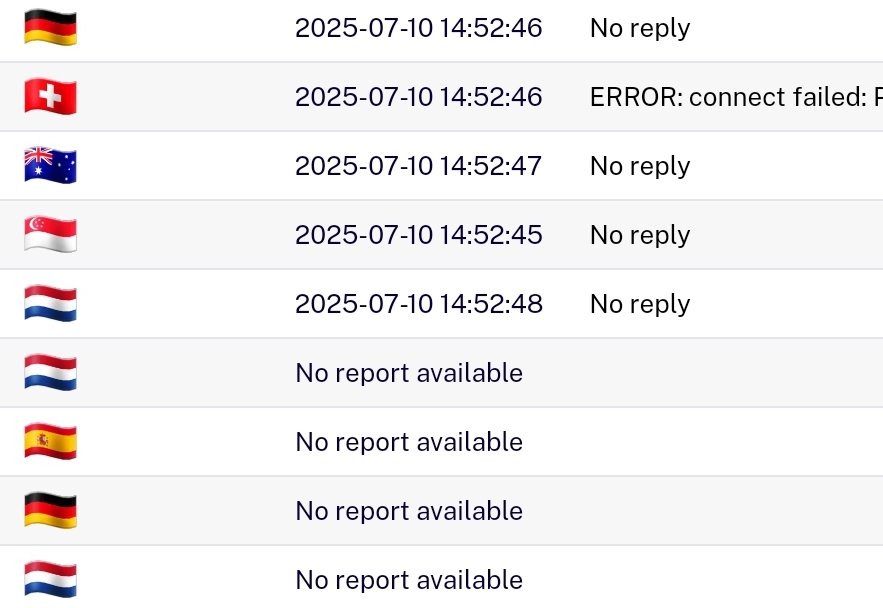
I understand the issue is _not_ that packets NTP aren't getting through. The issue is that the probes don't report on the results of the measurement ("no report available"), which they should do even when they don't get a response (which they should report with "no reply", or potentially an error message they got back). It's not only in the UI, but the data retrievable from the API is also lacking those reports. 12.07.2025 13:43:27 Max Grobecker <max.grobecker@ml.grobecker.info>:
Hi Marco, Hi Giovane,
do you know if this only affects ntp0.testdns.nl or could it be a problem with NTP packets in general? Also, did you do traceroutes/MTRs to the affected probes to see, if there are similarities in routing – like the same transit carrier? In the past, some carriers (CenturyLink, as an example) had traffic filter rules in place on their edges to prevent NTP reflection or amplification attacks, that killed regular NTP traffic as well, so I assume this could be the case here, too, not necessarily with CenturyLink/Colt as the transit.
You could try doing a traceroute with port 123/UDP as the source towards these probes to see, if the packets get eaten on some network demarcation:
traceroute -U --sport 123 <ip-of-the-probe>
You will likely not get an answer on the last 1-2 hops (because NAT and stateful firewalls), but if there's a carrier in between that discards traffic, the traceroute is noticeable shorter.
If it helps, you can try with my server ntp2.301-moved.de as well – I have access to sflow data from that host, so I can precisely tell if there have been answer packets coming from that system.
Greetings, Max ----- To unsubscribe from this mailing list or change your subscription options, please visit: https://mailman.ripe.net/mailman3/lists/ripe-atlas.ripe.net/ As we have migrated to Mailman 3, you will need to create an account with the email matching your subscription before you can change your settings. More details at: https://www.ripe.net/membership/mail/mailman-3-migration/
{kind=link}
which they should do even when they don't get a response (which they should report with "no reply", or potentially an error message they got back)
In fact, I can't shake the impression that only those probes that did _not_ get a reply, or got an error message, are the only ones reporting. And those probes that _did_ get a reply don't report it. 12.07.2025 13:54:42 via ripe-atlas <ripe-atlas@ripe.net>:
I understand the issue is _not_ that packets NTP aren't getting through.
The issue is that the probes don't report on the results of the measurement ("no report available"), which they should do even when they don't get a response (which they should report with "no reply", or potentially an error message they got back).
It's not only in the UI, but the data retrievable from the API is also lacking those reports.
12.07.2025 13:43:27 Max Grobecker <max.grobecker@ml.grobecker.info>:
Hi Marco, Hi Giovane,
do you know if this only affects ntp0.testdns.nl or could it be a problem with NTP packets in general? Also, did you do traceroutes/MTRs to the affected probes to see, if there are similarities in routing – like the same transit carrier? In the past, some carriers (CenturyLink, as an example) had traffic filter rules in place on their edges to prevent NTP reflection or amplification attacks, that killed regular NTP traffic as well, so I assume this could be the case here, too, not necessarily with CenturyLink/Colt as the transit.
You could try doing a traceroute with port 123/UDP as the source towards these probes to see, if the packets get eaten on some network demarcation:
traceroute -U --sport 123 <ip-of-the-probe>
You will likely not get an answer on the last 1-2 hops (because NAT and stateful firewalls), but if there's a carrier in between that discards traffic, the traceroute is noticeable shorter.
If it helps, you can try with my server ntp2.301-moved.de as well – I have access to sflow data from that host, so I can precisely tell if there have been answer packets coming from that system.
Greetings, Max
which they should do even when they don't get a response (which they should report with "no reply", or potentially an error message they got back)
In fact, I can't shake the impression that only those probes that did _not_ get a reply, or got an error message, are the only ones reporting. And those probes that _did_ get a reply don't report it.
I understand the issue is _not_ that packets NTP aren't getting through.
Yeah, I agree with these things you said . I tried to figure out if there was something odd to Marco's responses, but got nothing. But I did run an atlas measurement to your server, using the same probe's as Marco's original meassuremnet; https://atlas.ripe.net/measurements/117694460/overview Only two did not report the results So I dunno what to make of it /giovane
Hi Max,
do you know if this only affects ntp0.testdns.nl or could it be a problem with NTP packets in general?
AFIK it's only with this (odd) server from Marco, which runs his own code: https://github.com/mdavids/ntptools/tree/main/go/fake-ntp-server I've done many measurements with NTP in the past and have not seen such level of lack of responses. I thought it could be some sanitation on Atlas side, like, if some values would be too odd... like ,ref_timestamp > transmit_ts (violation of RFC) (I only found two probes which have strange processing time on the client -- like, how long it took to capture the packet from when it was crated -- one is -50s, the other is 100s) But I could not find any other more severe issues for the other missing 40 probes (i pushed an update on the data analysis at [0])
Also, did you do traceroutes/MTRs to the affected probes to see, if there are similarities in routing – like the same transit carrier? In the past, some carriers (CenturyLink, as an example) had traffic filter rules in place on their edges to prevent NTP reflection or amplification attacks, that killed regular NTP traffic as well, so I assume this could be the case here, too, not necessarily with CenturyLink/Colt as the transit.
no clue, it could be
You could try doing a traceroute with port 123/UDP as the source towards these probes to see, if the packets get eaten on some network demarcation:
traceroute -U --sport 123 <ip-of-the-probe>
I guess I need to update my traceroute for it.. the json on my repositiory [0] has the probe Ips in case you wanna give a shot
If it helps, you can try with my server ntp2.301-moved.de as well – I have access to sflow data from that host, so I can precisely tell if there have been answer packets coming from that system.
Let's see if the Atlas folks can confirm something on their side.,like sanitaion or something thanks a lot for your help
FWIW: I compiled the probe and couldn't find anything out of the ordinary: ./busybox evntp -6 -c 3 -w 4000 ntp0.testdns.nl RESULT { "dst_name":"ntp0.testdns.nl", "ttr":109.453445, "dst_addr":"2a02:2308:20:0:216:3eff:fe85:f45c", "src_addr":"2001:1c00:c081:ed00:201:c0ff:fe06:3551", "proto":"UDP", "af": 6, "li": "no", "version": 4, "mode": "server", "stratum": 1, "poll": 128, "precision": 1.19209e-07, "root-delay": 0, "root-dispersion": 0, "ref-id": "XFUN", "ref-ts": 3961497676.014892578, "result": [ { "origin-ts": 3961497975.998575211, "receive-ts": 3961497976.014892578, "transmit-ts": 3961497976.014945984, "final-ts": 3961497976.027197838, "rtt": 0.028570, "offset": -0.002033 }, { "poll": 256, "precision": 3.72529e-09, "ref-ts": 3961497676.041306019, "origin-ts": 3961497976.027345181, "receive-ts": 3961497976.041306019, "transmit-ts": 3961497976.041354656, "final-ts": 3961497976.051036835, "rtt": 0.023643, "offset": -0.002139 }, { "poll": 256, "precision": 1.49012e-08, "ref-ts": 3961497676.063885689, "origin-ts": 3961497976.051280022, "receive-ts": 3961497976.063885689, "transmit-ts": 3961497976.063924313, "final-ts": 3961497976.072422028, "rtt": 0.021104, "offset": -0.002054 } ] } ./busybox evntp -6 -c 1 ntp1.testdns.nl RESULT { "dst_name":"ntp1.testdns.nl", "ttr":479.530349, "dst_addr":"2a05:f480:1800:2898:5400:5ff:fe7c:8c82", "src_addr":"2001:1c00:c081:ed00:201:c0ff:fe06:3551", "proto":"UDP", "af": 6, "li": "no", "version": 4, "mode": "server", "stratum": 1, "poll": 1024, "precision": 7.45058e-09, "root-delay": 0, "root-dispersion": 0, "ref-id": "XFUN", "ref-ts": 3961497821.676918507, "result": [ { "origin-ts": 3961498121.667407990, "receive-ts": 3961498121.676918507, "transmit-ts": 3961498121.676956654, "final-ts": 3961498121.687090874, "rtt": 0.019645, "offset": 0.000312 } ] } -- Marco
Interestingly, measurements that don't yield _any_ results at all (i.e., not even "no response" or some explicit error condition) are marked as "Failed". That status is documented, but I had never seen it before. As far as I could see so far, when the evntp command is run as part of an actual probe, data is indeed generated as well. It can be found in the spool directory. And it disappears regularly from that directory, suggesting that it is being transmitted to the infrastructure. In turn suggesting, and supporting Marco's hypothesis, that something on the infrastructure side may be subsequently dropping the data. One thing I noted with this explicitly misbehaving server: When a probe sends multiple packets per interval (default is to send three), those are currently sent back to back. I.e., unless there is packet loss, the second and third request are sent as soon as the response to the previous request has been received. As consequence, the values of the majority of fields in the responses are typically the same between responses, e.g., ref-id, poll, precision, stratum, version, mode, even ref-ts. As such, they are at the top level of the JSON object. And the "result" structure only has the fields that vary between the packets, i.e., the timestamps related to the actual packet transmission (and derived values). With the explicitly misbehaving server, however, some of the fields that would typically not change between back-to-back responses, or rather rarely only, _do_ change from one response to the next. E.g., the poll and precision fields. In those cases, there still is an entry at the top level of the JSON object, I guess perhaps derived from the first response packet. But then, the result structure would additionally have entries for those types of fields in a response where the value differs from the one at the top level. Obviously speculating, and certainly not foregoing a deeper look by RIPE Atlas staff, but maybe the infrastructure discards such probe reports for whatever reason. It seems the explicitly misbehaving server has been replaced by a more sane one (albeit apparently not synchronized), so one cannot at this time follow up on the above hypothesis. E.g., a measurement where only a single packet is being sent per interval should succeed as it wouldn't have the same type of values at different levels of the JSON structure. On 14.07.25 18:09, Marco Davids (SIDN) via ripe-atlas wrote:
FWIW:
I compiled the probe and couldn't find anything out of the ordinary:
./busybox evntp -6 -c 3 -w 4000 ntp0.testdns.nl RESULT { "dst_name":"ntp0.testdns.nl", "ttr":109.453445, "dst_addr":"2a02:2308:20:0:216:3eff:fe85:f45c", "src_addr":"2001:1c00:c081:ed00:201:c0ff:fe06:3551", "proto":"UDP", "af": 6, "li": "no", "version": 4, "mode": "server", "stratum": 1, "poll": 128, "precision": 1.19209e-07, "root-delay": 0, "root- dispersion": 0, "ref-id": "XFUN", "ref-ts": 3961497676.014892578, "result": [ { "origin-ts": 3961497975.998575211, "receive-ts": 3961497976.014892578, "transmit-ts": 3961497976.014945984, "final-ts": 3961497976.027197838, "rtt": 0.028570, "offset": -0.002033 }, { "poll": 256, "precision": 3.72529e-09, "ref-ts": 3961497676.041306019, "origin- ts": 3961497976.027345181, "receive-ts": 3961497976.041306019, "transmit-ts": 3961497976.041354656, "final-ts": 3961497976.051036835, "rtt": 0.023643, "offset": -0.002139 }, { "poll": 256, "precision": 1.49012e-08, "ref-ts": 3961497676.063885689, "origin-ts": 3961497976.051280022, "receive-ts": 3961497976.063885689, "transmit-ts": 3961497976.063924313, "final-ts": 3961497976.072422028, "rtt": 0.021104, "offset": -0.002054 } ] }
./busybox evntp -6 -c 1 ntp1.testdns.nl RESULT { "dst_name":"ntp1.testdns.nl", "ttr":479.530349, "dst_addr":"2a05:f480:1800:2898:5400:5ff:fe7c:8c82", "src_addr":"2001:1c00:c081:ed00:201:c0ff:fe06:3551", "proto":"UDP", "af": 6, "li": "no", "version": 4, "mode": "server", "stratum": 1, "poll": 1024, "precision": 7.45058e-09, "root-delay": 0, "root- dispersion": 0, "ref-id": "XFUN", "ref-ts": 3961497821.676918507, "result": [ { "origin-ts": 3961498121.667407990, "receive-ts": 3961498121.676918507, "transmit-ts": 3961498121.676956654, "final-ts": 3961498121.687090874, "rtt": 0.019645, "offset": 0.000312 } ] }

Hi, (I understand there were many more messages about this recently, somewhat skipping ahead...) I executed these just now against the same target(s), and results look good: https://atlas.ripe.net/measurements/118369580 https://atlas.ripe.net/measurements/118370167 If I understand correctly things changed on the server side as well, but I'm not 100% sure we can conclude the issue was there to begin with? If so, we can work together and do some controlled experiments - observing closer what the probes get and whether they pass those results along. There is a chance we could improve handling of bad responses, or perhaps there's a bug that eats up good but unexpected responses. Cheers, Robert On 10-07-2025 18:01, Marco Davids (SIDN) via ripe-atlas wrote:
Dear list,
If anyone knows, or is able to figure out, why most (but not all) Atlas probes don’t report results for NTP measurements to ntp0.testdns.nl, I’d appreciate your insights.
Examples:
https://atlas.ripe.net/measurements/116922622/
https://atlas.ripe.net/measurements/116946257/
https://atlas.ripe.net/measurements/116830921/
Ping works:
https://atlas.ripe.net/measurements/116921717/
Thanks in advance.
----- To unsubscribe from this mailing list or change your subscription options, please visit: https://mailman.ripe.net/mailman3/lists/ripe-atlas.ripe.net/ As we have migrated to Mailman 3, you will need to create an account with the email matching your subscription before you can change your settings. More details at: https://www.ripe.net/membership/mail/mailman-3-migration/
----- To unsubscribe from this mailing list or change your subscription options, please visit: https://mailman.ripe.net/mailman3/lists/ripe-atlas.ripe.net/ As we have migrated to Mailman 3, you will need to create an account with the email matching your subscription before you can change your settings. More details at: https://www.ripe.net/membership/mail/mailman-3-migration/
Hi Robert, The intentionally misbehaving server is now under a different name/IPv6 address. https://atlas.ripe.net/measurements/118255807/ -> one packet per interval -> no obvious missing entries in the data (~300 total) https://atlas.ripe.net/measurements/118255806/ -> three packets per interval --> only 15 entries, while a similar number as for 118255807 were expected https://atlas.ripe.net/measurements/118255906/ -> ten packets per interval -> complete fail I note that those results that _are_ being reported for the measurement with three back-to-back requests per interval (118255806) all have the "poll" field "duplicated" at least once in the "result" substructure ("duplicated" in the sense discussed earlier). "Duplication" of, e.g., "precision" or "ref-ts", is present in the results for that measurement, so likely not an issue. Locally, I got 250 entries for each of those measurements (vs. 303 for 118255807 from Atlas), but due to how I got them, likely a few were missed. On 18.07.25 10:18, Robert Kisteleki wrote:
Hi,
(I understand there were many more messages about this recently, somewhat skipping ahead...)
I executed these just now against the same target(s), and results look good: https://atlas.ripe.net/measurements/118369580 <https://atlas.ripe.net/ measurements/118369580> https://atlas.ripe.net/measurements/118370167 <https://atlas.ripe.net/ measurements/118370167>
If I understand correctly things changed on the server side as well, but I'm not 100% sure we can conclude the issue was there to begin with? If so, we can work together and do some controlled experiments - observing closer what the probes get and whether they pass those results along. There is a chance we could improve handling of bad responses, or perhaps there's a bug that eats up good but unexpected responses.
Cheers, Robert
On 10-07-2025 18:01, Marco Davids (SIDN) via ripe-atlas wrote: > Dear list, > > If anyone knows, or is able to figure out, why most (but not all) Atlas > probes don’t report results for NTP measurements to ntp0.testdns.nl <http://ntp0.testdns.nl>, I’d > appreciate your insights. > > Examples: > > https://atlas.ripe.net/measurements/116922622/ <https:// atlas.ripe.net/measurements/116922622/> > > https://atlas.ripe.net/measurements/116946257/ <https:// atlas.ripe.net/measurements/116946257/> > > https://atlas.ripe.net/measurements/116830921/ <https:// atlas.ripe.net/measurements/116830921/> > > Ping works: > > https://atlas.ripe.net/measurements/116921717/ <https:// atlas.ripe.net/measurements/116921717/> > > Thanks in advance. > > > ----- > To unsubscribe from this mailing list or change your subscription options, please visit: https://mailman.ripe.net/mailman3/lists/ripe- atlas.ripe.net/ <https://mailman.ripe.net/mailman3/lists/ripe- atlas.ripe.net/> > As we have migrated to Mailman 3, you will need to create an account with the email matching your subscription before you can change your settings. > More details at: https://www.ripe.net/membership/mail/mailman-3- migration/ <https://www.ripe.net/membership/mail/mailman-3-migration/>
Forgot to mention explicitly: Obviously, the more packets per cycle, the higher the likelihood for "field duplication" between responses in the same cycle. For three packets per cycle, it was low enough for at least some cycles to not have the duplication of the poll field. On 18.07.25 11:40, via ripe-atlas wrote:
Hi Robert,
The intentionally misbehaving server is now under a different name/IPv6 address.
https://atlas.ripe.net/measurements/118255807/ -> one packet per interval -> no obvious missing entries in the data (~300 total) https://atlas.ripe.net/measurements/118255806/ -> three packets per interval --> only 15 entries, while a similar number as for 118255807 were expected https://atlas.ripe.net/measurements/118255906/ -> ten packets per interval -> complete fail
I note that those results that _are_ being reported for the measurement with three back-to-back requests per interval (118255806) all have the "poll" field "duplicated" at least once in the "result" substructure ("duplicated" in the sense discussed earlier). "Duplication" of, e.g., "precision" or "ref-ts", is present in the results for that measurement, so likely not an issue.
Locally, I got 250 entries for each of those measurements (vs. 303 for 118255807 from Atlas), but due to how I got them, likely a few were missed.
On 18.07.25 10:18, Robert Kisteleki wrote:
Hi,
(I understand there were many more messages about this recently, somewhat skipping ahead...)
I executed these just now against the same target(s), and results look good: https://atlas.ripe.net/measurements/118369580 <https://atlas.ripe.net/ measurements/118369580> https://atlas.ripe.net/measurements/118370167 <https://atlas.ripe.net/ measurements/118370167>
If I understand correctly things changed on the server side as well, but I'm not 100% sure we can conclude the issue was there to begin with? If so, we can work together and do some controlled experiments - observing closer what the probes get and whether they pass those results along. There is a chance we could improve handling of bad responses, or perhaps there's a bug that eats up good but unexpected responses.
Cheers, Robert
On 10-07-2025 18:01, Marco Davids (SIDN) via ripe-atlas wrote: > Dear list, > > If anyone knows, or is able to figure out, why most (but not all) Atlas > probes don’t report results for NTP measurements to ntp0.testdns.nl <http://ntp0.testdns.nl>, I’d > appreciate your insights. > > Examples: > > https://atlas.ripe.net/measurements/116922622/ <https:// atlas.ripe.net/measurements/116922622/> > > https://atlas.ripe.net/measurements/116946257/ <https:// atlas.ripe.net/measurements/116946257/> > > https://atlas.ripe.net/measurements/116830921/ <https:// atlas.ripe.net/measurements/116830921/> > > Ping works: > > https://atlas.ripe.net/measurements/116921717/ <https:// atlas.ripe.net/measurements/116921717/> > > Thanks in advance. > > > ----- > To unsubscribe from this mailing list or change your subscription options, please visit: https://mailman.ripe.net/mailman3/lists/ripe- atlas.ripe.net/ <https://mailman.ripe.net/mailman3/lists/ripe- atlas.ripe.net/> > As we have migrated to Mailman 3, you will need to create an account with the email matching your subscription before you can change your settings. > More details at: https://www.ripe.net/membership/mail/mailman-3- migration/ <https://www.ripe.net/membership/mail/mailman-3- migration/>
participants (5)
-
 Giovane C. M. Moura
Giovane C. M. Moura -
 Marco Davids (SIDN)
Marco Davids (SIDN) -
 Max Grobecker
Max Grobecker -
 ripe@nurfuerspam.de
ripe@nurfuerspam.de -
 Robert Kisteleki
Robert Kisteleki